协议栈主要负责对网卡芯片从网络上抓到的包进行过滤、协议分析并根据数据包的内容传输给不同的应用,这个应用也许是协议栈内的,也许是协议栈之上的。
网络上流行的开源TCP/IP协议栈有很多,例如:LWIP、uC/IP,uIP等等,均是为嵌入式平台提供的。
本文要介绍的协议栈是InterNiche公司推出的商用嵌入式协议栈NicheStack。
相比其他几款协议栈,之所以选择NicheStack来介绍,因为:
LWIP:是目前嵌入式行业应用范围最广泛的协议栈,也是我当前所在公司用的协议栈,为了技术上避嫌,所以不讲;
uC/IP:由于脱胎于ucOS,移植性稍差;
uIP:轻量级协议栈,太简单,没意思;
其他:没玩儿过,不了解;
注:关于NicheStack的官方资料请访问:http://www.iniche.com/
(1) 基础结构
NicheStack协议栈是通过回调函数的形式将数据报文层层传递,在整个回调路径的起点有两种设计方式:查询和中断。(其实大多数异步通信机制中都可以用这两种方式处理数据)
所谓查询就是在MCU中开启一个循环任务,周期地去询问网卡芯片是否有数据包到来,如果有则捡出数据包并传递给协议栈去处理;
中断的方式则是每当网卡芯片有数据包到来,就产生一个中断信号,在MCU中为该中断信号编写一段服务例程处理收到的数据。
查询方式的缺点是,当数据量比较大的时候,受限于MCU的执行速度,很可能产生丢包的情况;
中断方式的缺点是,会打断正在执行的其他低优先级任务,降低系统整体性能;
考虑到实际应用场合中以太网报文通常都是毫秒级别,尤其是在一些情况复杂的网络中,数据报文间隔会达到微秒级别,所以数据包的接收建议采用DMA+中断的形式,而为了兼顾系统其他模块的性能,协议栈的回调处理则采用查询的方式。
NicheStack协议栈就为这样的方式提供了便捷的实现途径。
在NicheStack中所有的网络数据包都是存放在一个名叫“netbuf”的结构体中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | struct netbuf { struct netbuf * next; /* queue link */ char * nb_buff; /* beginning of raw buffer */ unsigned nb_blen; /* length of raw buffer */ char * nb_prot; /* beginning of protocol/data */ unsigned nb_plen; /* length of protocol/data */ long nb_tstamp; /* packet timestamp */ struct net * net; /* the interface (net) it came in on, 0-n */ unsigned long fhost; /* IP address asociated with packet */ unsigned short type; /* IP==0800 filled in by recever(rx) or net layer.(tx) */ unsigned inuse; /* use count, for cloning buffer */ /* ...... */ }; typedef struct netbuf * PACKET; /* struct netbuf in netbuf.h */ |
不同层次的协议解析均通过这个结构来传递数据;
嵌入式平台上的以太网通信功能是非常典型的低速、高速系统匹配,通常解决这类问题的办法就是增加缓冲队列。
NicheStack为避免嵌入式平台频繁申请内存空间导致内存碎片的问题,在初始化的时候就预先申请好协议栈运行时需要的所有报文存储数据结构,并形成队列,但预先申请存储空间无法预知以太网收取的实际报文大小,如果全部使用最大尺寸又很浪费空间,于是NicheStack设计了两个预置队列:bigfreeq与lilfreeq;
其中,bigfreeq用于存储长度大的数据包,lilfreeq用于存储长度小的数据包。
两个队列中数据存储区的大小,以及队列长度在ipport.h中定义。
1 2 3 4 5 6 | /* define number and sizes of free buffers */ #define NUMBIGBUFS 12 #define NUMLILBUFS 8 #define BIGBUFSIZE 1536 #define LILBUFSIZE 128 <img class="alignnone size-full wp-image-97" src="http://dongzhichao.com/wp-content/uploads/2016/12/tcpip_8.png" alt="tcpip_8" width="635" height="608" /> |
之所以将PACKET结构与buffer分开画,是因为NicheStack在lpport.h中为两个结构的内存申请提供了不同的接口定义:NB_ALLOC与BB_ALLOC,之所以这样设计,是因为某些系统可能需要将Buffer存储到SRAM或者DMA专用RAM中以提高存取速度。
队列的实现在net文件夹下的q.h与q.c中,队列中数据包的申请与释放使用pk_alloc与pk_free接口,实现在net文件夹下的pktallock.c文件中(都是基本的数据结构操作,就不细说了)。
(2) 中断函数
NicheStack并不会提供完整的驱动层代码,以太网中断函数一般根据具体芯片略有不同,下图是一种常见的以太网中断例程实现流程:
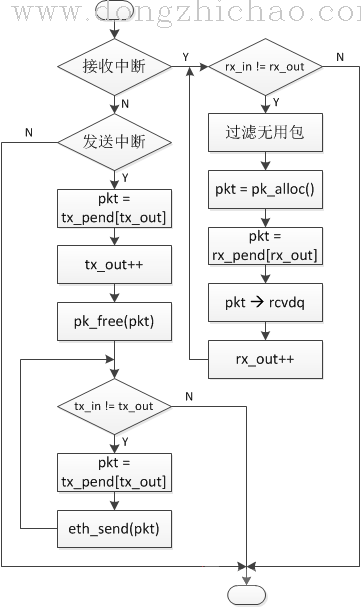
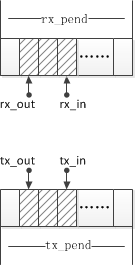
在这个中断服务例程中,除了大小包队列还用到了两个缓冲区rx_pend与tx_pend,如果用到了DMA,那么这两个缓冲区的指针可以直接指向DMA RAM,其具体结构如下:
值得一提的是,根据我们上一篇中所讲的TCP/IP五层参考结构,这个中断函数所在的层次属于自底向上的第二层——网络接口层,而物理层对应的处理过程实现在了网卡芯片中,在802.3的规范中,网卡芯片实际从物理媒体上接收到的信号解调后报文格式看起来是这个样子的:

FCS通常是32为的CRC校验,网卡芯片(也就是物理层)会处理掉前导码和FCS,将错误的报文数据丢弃,同时会生成一条错误记录,大多数网卡芯片都会提供错误帧计数寄存器,有些网卡芯片还会分门别类地将不同类型的错误分别记录到不同的寄存器或者同个寄存器不同的位中,在实际的程序开发中工程师可以通过这类寄存器协助网络或者硬件调试。
经过网卡芯片过滤后的数据帧会被传递给网络接口层,在有些代码中网络接口层也被称为PHY层或者MAC层,名称很混乱,不过并不需要太过纠结,重要的是在这一层次处理了以太网数据包中的MAC报文头:

其中,目的地址、源地址也就是我们常说的MAC地址,再加上类型这三个字段一共14个Bytes,也被称为MAC头,MAC头的定义在Ether.h文件中:
1 2 3 4 5 6 7 | /* ethernet packet header */ START_PACKED_STRUCT(ethhdr) unsigned char e_dst[6]; unsigned char e_src[6]; unsigned short e_type; END_PACKED_STRUCT(ethhdr) |
在上面中断服务例程中接收中断分支中“过滤无用包”的过程,很大一部分工作就是根据MAC头中的信息丢弃掉当前系统不关心的数据包,例如,过滤掉所有超过70个Bytes的广播包,或者只接收类型为0x0800(IP)和0x0806(ARP)的数据报文。
(3) 报文的回调与分层处理
通过以太网中断接收到的所有报文经过过滤后都会被缓冲到rcvdq(定义在mip文件夹下的m_ipnet.c文件)这个队列中供协议栈处理。
最终通过在任务循环中调用一个名为pktdemux的函数(m_ipnet.c文件中)处理所有缓存在rcvdq队列中的报文。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | void pktdemux() { PACKET pkt; NET ifc; /* interface packet came from */ IFMIB mib; char * eth; unsigned short eth_type; while (rcvdq.q_len) { LOCK_NET_RESOURCE(RXQ_RESID); pkt = (PACKET)q_deq(&rcvdq); UNLOCK_NET_RESOURCE(RXQ_RESID); /* ...... */ if (pkt->type == IPTP) /* IP type */ { LOCK_NET_RESOURCE(NET_RESID); ip_rcv(pkt); UNLOCK_NET_RESOURCE(NET_RESID); continue; } if (pkt->type == ARPTP) /* ARP type */ { LOCK_NET_RESOURCE(NET_RESID); arprcv(pkt); UNLOCK_NET_RESOURCE(NET_RESID); continue; } /* ...... */ LOCK_NET_RESOURCE(FREEQ_RESID); pk_free(pkt); /* return to free buffer */ UNLOCK_NET_RESOURCE(FREEQ_RESID); } } |
协议栈的实现是嵌入式系统分层设计的典范,每层只处理属于自己层次的数据,网络接口层只处理MAC报头数据,网络层只关心网络层协议数据,传输层只关心传输层协议数据。
以一个简单的UDP协议为例,假设局网内的一个UDP客户端向UDP服务端发送了一条请求数据,请求数据在协议栈中的每层处理流程可由下图表示:
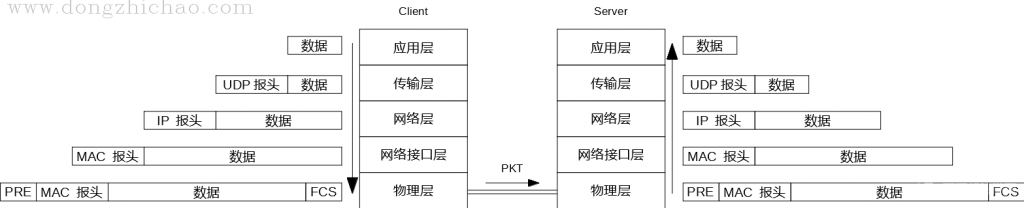
关于上图中每层的报头《TCP/IP详解》这本书中有十分详细的描述,我没人家写的好,就不在这里赘述了。
另外,这张图只是一张简图,在正常的通信中,如果这条请求是第一次发给这个IP地址,那么还涉及到使用ARP协议来查询目的MAC地址这个过程(关于ARP协议的功能请参考《计算机网络》这本书)。
NicheStack为近期常用的IP地址维护了一张ARP表——arp_table(定义在了arp.h文件中),通过MAXARPS宏来声明ARP表的大小:
1 2 | #define MAXARPS 8 /* maximum mumber of arp table entries */ extern struct arptabent arp_table[MAXARPS]; /* the actual table */ |
可以根据系统资源以及网络的容量和负载来修改ARP表的大小,以达到最优的通信效果。
由于篇幅所限,关于各层协议的详细代码就不再这里记述了,NicheStack对协议解析的实现很大程度上参考了《TCP/IP详解 卷二》中的代码。
除了TCP协议之外,其他的协议的实现都很简单,哪天如果有时间再专门开个专题讲讲TCP通信的内部机制。