快排可以说是我们平时用的最多的一种排序算法,没有之一。尽管效率不是很稳定,最坏的情况下会达到O(n^2)的时间复杂度,但在元素互异的时候,时间复杂度的期望可以达到O(nlgn)。
快排的基本思想与分治法类似,不过略有不同,分治法是自底向上合并,快排是自顶向下划分。
算法原理是:
(1) 在待排序的数据中选择一个Key,通常是第一个数据或者最后一个数据;
(2) 使得序列中所有比Key小的数据都放在Key的一边,而比Key大的都放在Key的另一边;
(3) 同理排序Key左侧和右侧两个序列;
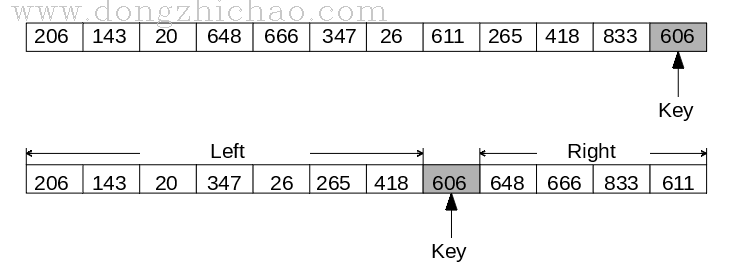
举例说明:
快排的基本思想与分治法类似,不过略有不同,分治法是自底向上合并,快排是自顶向下划分。
算法原理是:
(1) 在待排序的数据中选择一个Key,通常是第一个数据或者最后一个数据;
(2) 使得序列中所有比Key小的数据都放在Key的一边,而比Key大的都放在Key的另一边;
(3) 同理排序Key左侧和右侧两个序列;
举例说明:
由于原理十分简单,废话不多说了,直接上代码:
#define CHANGE_TWO_NODE(x, y) do{(x)^=(y);(y)^=(x);(x)^=(y);}while(0) static int __partition(int* in, int p, int r) { int i, j, k; k = r; for(i = p-1, j = p; j < r; ++j){ if(in[j] <= in[k]){ ++i; if(i != j) CHANGE_TWO_NODE(in[i], in[j]); } } if(i+1 != k) CHANGE_TWO_NODE(in[i+1], in[k]); return i+1; } static void __quick_sort(int* in, int p, int r) { if(p < r){ int q; q = __partition(in, p, r); __quick_sort(in, p, q-1); __quick_sort(in, q+1, r); } } int quick_sort(int* in, int len) { __quick_sort(in, 0, len-1); return 0; } |
同样,代码已经上传到我的github:
https://github.com/plumpyomi/algorithm.git
https://github.com/plumpyomi/algorithm.git